docker仓库优化
自19年底上线docker仓库服务,很长一段时间服务都比较稳定,但随着业务上量,有些问题开始出现…
最初架构
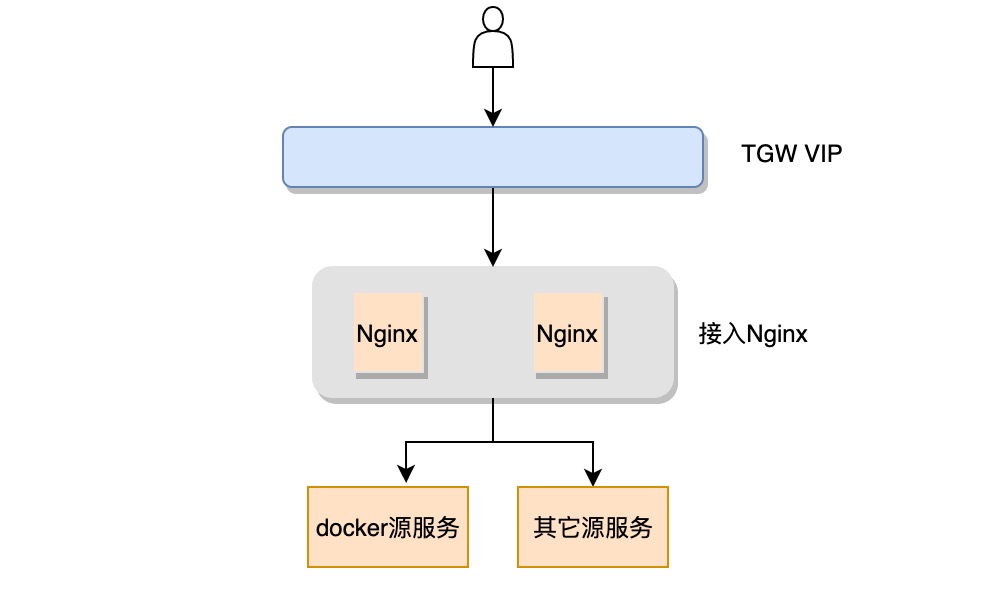
最初docker仓库是定位于开发测试用,得易于我们的接入TGW VIP在各个网络专区基本都能连通,很快吸引了一大批用户把镜像上传到我们这里。
作为一个公司级的源服务,不少业务直接将镜像应用到了生产环境。 随着业务容器化上云的趋势越来越强,k8s集群的量和规模都越来越大,对镜像仓库造成了不少压力。6月份因为请求突增,问题开始出现,主要是docker仓库存储ceph上面遇到的两个问题:
- ceph rgw接入机器网卡打满
- 并发量高ceph rgw处理线程满
因为nginx接入层机器比ceph rgw接入机器数量多,提供的带宽能力是不等的。rgw是多线程同步阻塞IO模型,一个请求会占用一个处理线程,镜像因为体积大处理耗时多,在并发量高的时候处理线程会被占满,新请求得不到aceept超时。
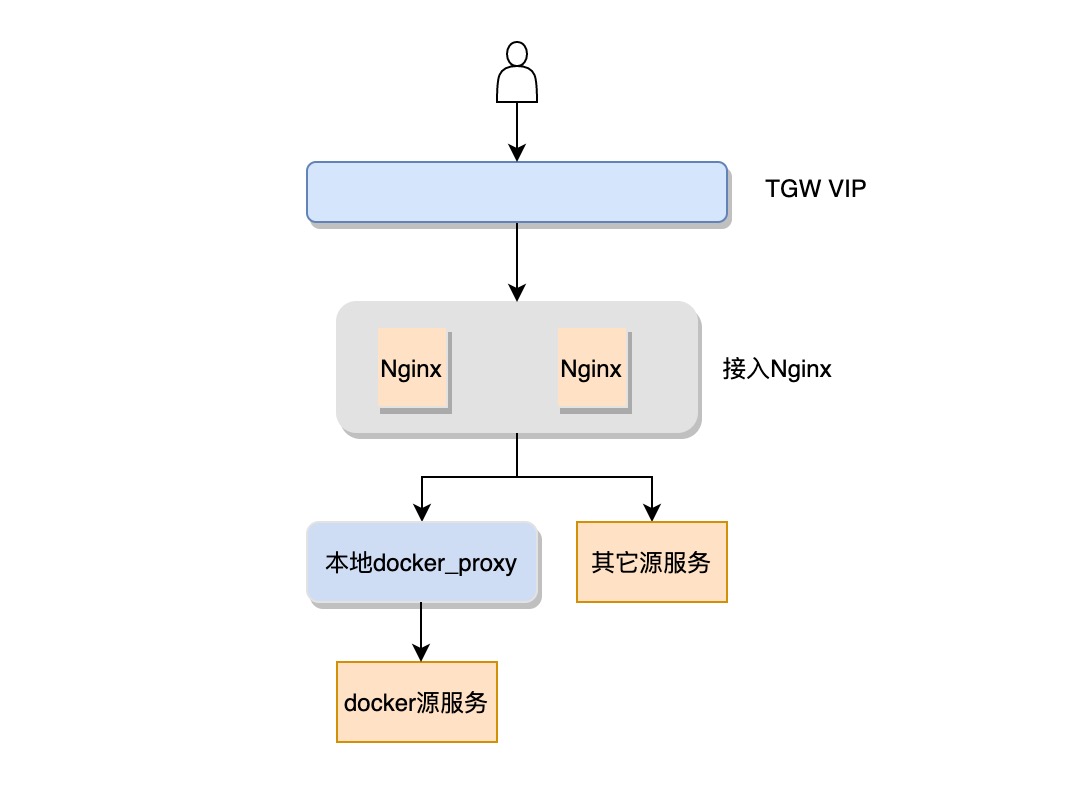
接入层缓存
除了给ceph rgw扩容外,我们紧急在接入层上线了docker proxy组件。 此组件的主要功能是代理镜像下载请求:
- 如果本地无缓存,回源到ceph拉一份,否则直接从本地返回
- 如果并发下载同一个镜像且本地没有缓存,proxy会在本地hold住所有请求,只回源一次,避免对ceph造成冲击
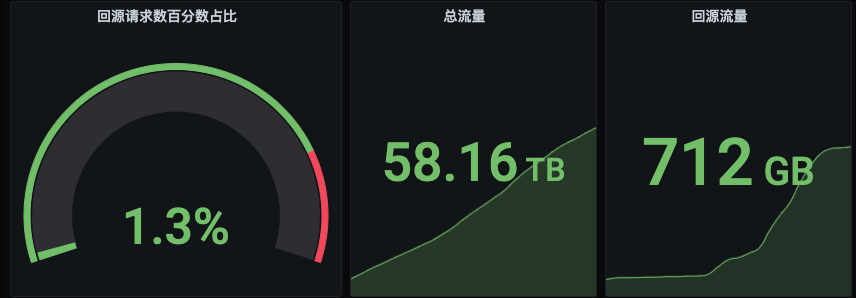
docker proxy上线后,极大缓解了ceph的压力。回源请求数和流量约1%。
主站流控 & 多地域就近接入
上线docker proxy后,虽然ceph的流量已经没什么压力,但是我们自身接入层nginx的流量却很容易被打满。
可能解决办法有:
- 扩容接入层Nginx缓解问题,但是TGW VIP本身也是有带宽上限,盲目扩容势必会给VIP带来压力,影响链路质量
- 增加TGW VIP,缺点是要去重新申请打通网络策略
不管是扩容Nginx,还是增加TGW VIP,我们接入这一套都要去完整部署一次,相对比较麻烦一些,我们采用了主站流控+多地域就近接入方案。
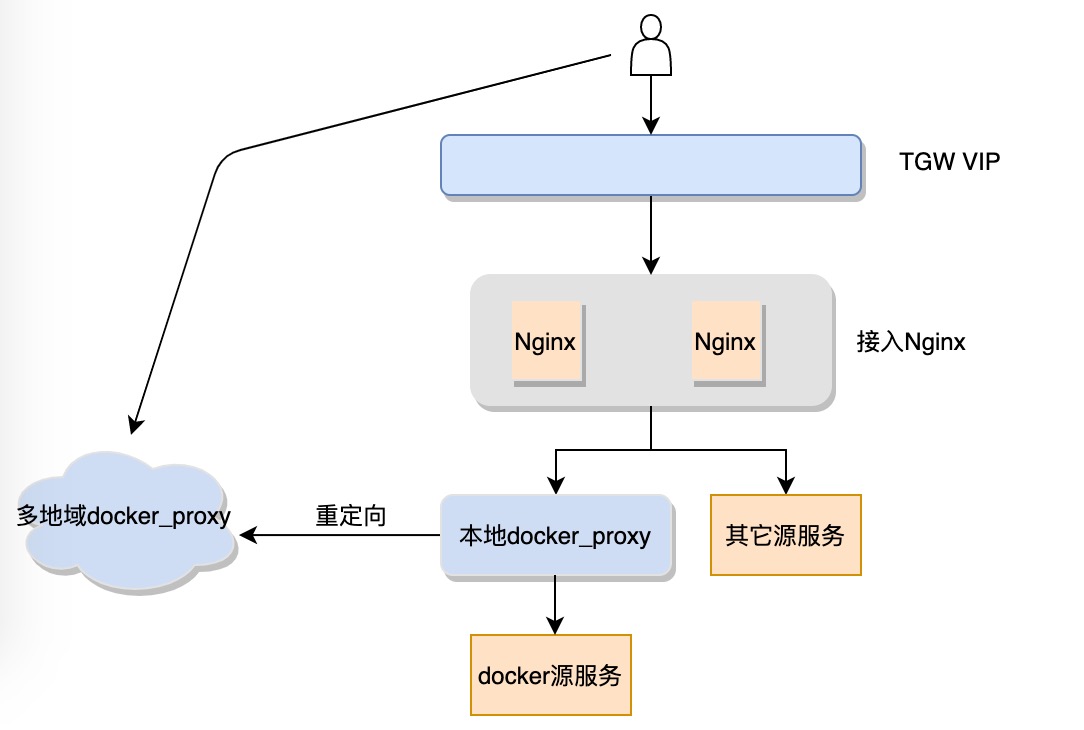
为了避免业务k8s集群扩容对软件源主站造成影响,我们在主站对单个docker仓库命名空间以及系统全局的拉取流量进行控制,避免docker的大流量对其他源造成影响。
另外k8s集群基本部署在自研或者云机房,和我们接入服务器是可以直连的,流量可避免再通过VIP中转一次。因此我们在华南、华东、西南、华北主要地域部署docker proxy组件,针对有大流量下载的命名空间开启就近接入。主站接入层根据拉取机器的地域将请求重定向给最近的docker proxy节点去处理,这样既避免了主站的流量压力又提高了下载速度。
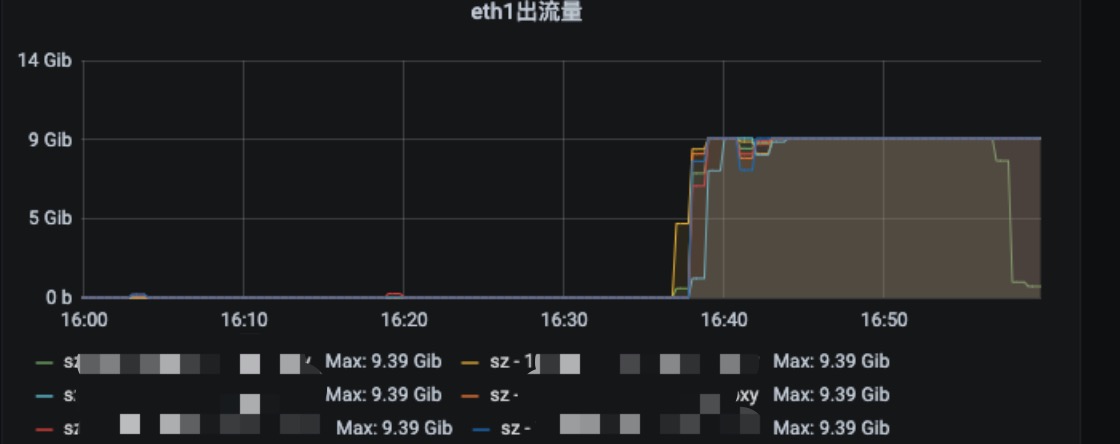
某业务扩容期间,华南接入点流量情况(万兆机器):
最后
这种大流量的场景,计成本的中心式服务始终会存在瓶颈,P2P或许才是最好的方案,但这个涉及到客户端改造,又是另外一个问题了…