Kafka消费的exactly-once
看一下kafka partion log图:
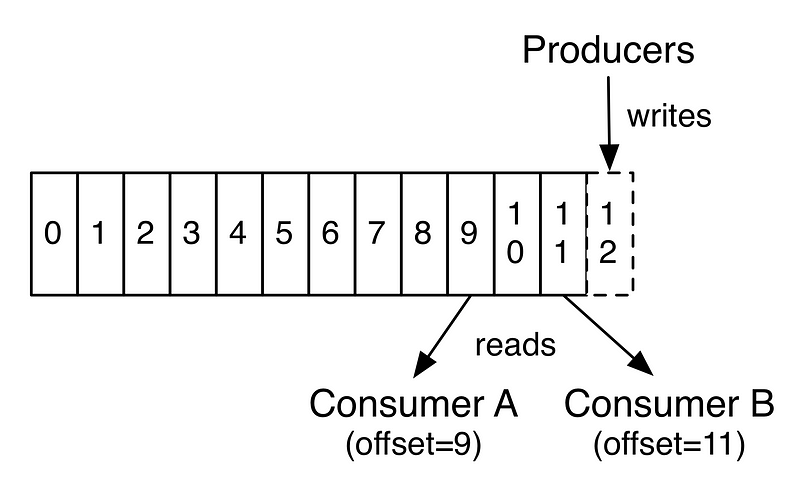
kafka保证每个topic的单partition内消息是有序的,producer追加写消息,并且每条消息带有唯一的offset,comuser可以控制从特定的offset从log读取消息。
一个典型的应用程序可能找下面这样:
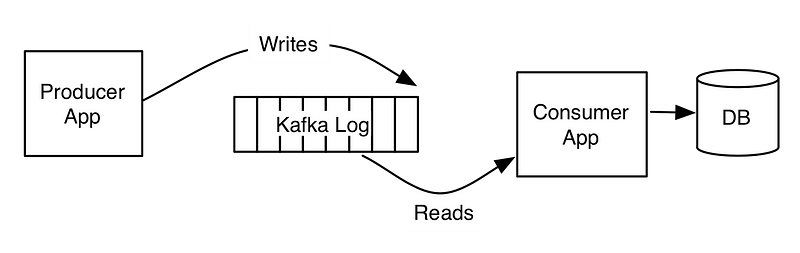
生产者往kafka写消息,消费者拉取消息后写入DB。这样一个应用程序如何实现exactly-once消息语义?
你可能会想到两个问题:
- 因为网络问题,生产者没有收到kafka broker的ACK,生产者进行重试,但实际上可能两条消息都投递成功了。如果不重试,消息可能就丢了。
At least onceVSAt most once - 消费者从log读取消息,更新offset,然后插入DB。如果在更新完offset后,程序crash消息未插入DB,消息就丢了。换成先插入DB,再更新offset,也会有问题,插入DB后程序crash,offset未更新成功,程序重启后就会重复读取消息。又是
At least onceVSAt most once
对于第一个问题,kafka给出了生产者幂等性的解决方案。
对于第二个问题,在数学意义上来说没法实现exactly-once, 参考FLP和TWO-GENERAL。
但在工程上面如何实现呢?其实第二个问题在传统单机程序或无状态服务上面我们也会经常碰到,最典型的就是重复插入问题,可简单通过唯一索引或主键来解决。
解决消费者的exactly-once可以通过幂等性,如果每条消息都有唯一ID,可以通过唯一索引来解决。也可以将offset存储在同一个DB中,通过事务的方式去更新DB,这个看具体的业务场景了。
如果通过幂等性的方式来实现,我们似乎可以不用kafka生产者的幂等性方案了,毕竟带来额外工作。
思考:
很多时候,我们会按批消费消息。比如可能会一次性拉取10条消息并行处理,这种服务改如何设计实现exactly-once?
参考:
https://medium.com/@jaykreps/exactly-once-support-in-apache-kafka-55e1fdd0a35f
https://hevodata.com/blog/kafka-exactly-once/